C++并发
参考自《C++ Concurrency In Action》
- 作者:Anthony Williams
- 译者:xiaoweiChen
线程管理
- 启动新线程
void Func1(); void Func2(int); void Foo::Func3(int); std::thread t1(Func1); std::thread t2(Func1, 0); std::thread t3(Func1, &Foo{}, 0); - 等待与分离
- obj.join()
- obj.detach()
- obj.joinable()
- 唯一标识符
- obj.get_id()
- std::this_thread::get_id()
- 其他
std::thread::hardware_concurrency()
共享数据
使用互斥保护数据
std::mutex
lock()try_lock()unlock()
基本用法
std::mutex m;
m.lock();
...
m.unlock();
避免死锁
多个互斥量锁住时,在所有地方应该以相同的顺序上锁,否则可能会造成死锁
std::mutex m1;
std::mutex m2;
void Func1()
{
m1.lock();
m2.lock();
...
m2.unlock();
m1.unlock();
}
void Func2()
{
m2.lock();
m1.lock();
// 应该和Func1顺序相同
// m1.lock();
// m2.lock();
...
m1.unlock();
m2.unlock();
}
或者一次锁住多个互斥量
std::mutex m1, m2;
std::lock(m1, m2);
...
m1.unlock();
m2.unlock();
std::lock_guard<>
互斥量的RAII模板类,不用手动lock()与unlock()
std::mutex m;
std::lock_guard<std::mutex> lg(m);
同时,可以获取并接管锁
std::mutex m1, m2;
std::lock(m1, m2);
std::lock_guard<std::mutex> lg1(m1, std::adopt_lock);
std::lock_guard<std::mutex> lg2(m2, std::adopt_lock);
std::scoped_lock<>
C++17中的新的RAII模板,与std::lock_guard<>相同,不过可以接受多个互斥量,对其上锁
std::mutex m1, m2;
std::scoped_lock<std::mutex> sl(m1, m2);
层级锁的实现
#include <climits>
#include <mutex>
#include <stdexcept>
class hierarchical_mutex {
public:
hierarchical_mutex(unsigned long value)
: hierarchy_value(value), previous_hierarchy_value(0) {}
void lock() {
check_hieratchy(); // 当前互斥量的层级与当前线程的层级相比较
internal_mutex.lock();
update_hierarchy(); // 将线程层级与当前层级同步
}
void unlock() {
if (this_hierarchy_value != hierarchy_value)
throw std::logic_error("mutex hierarchy violated");
this_hierarchy_value = previous_hierarchy_value;
internal_mutex.unlock();
}
bool try_lock() {
check_hieratchy();
if (!internal_mutex.try_lock())
return false;
update_hierarchy();
return true;
}
private:
void check_hieratchy() {
if (hierarchy_value >= this_hierarchy_value)
throw std::logic_error("mutex hierarchy violated");
}
void update_hierarchy() {
previous_hierarchy_value = this_hierarchy_value;
this_hierarchy_value = hierarchy_value;
}
private:
std::mutex internal_mutex;
const unsigned long hierarchy_value; // 当前锁的层级
unsigned long previous_hierarchy_value; // 当前锁的上一层的层级
static thread_local unsigned long this_hierarchy_value; // 线程的层级
};
thread_local unsigned long hierarchical_mutex::this_hierarchy_value{ULONG_MAX};
std::unique_lock<>
与std::lock_guard<>相似,不过前者只提供了析构接口,但std::unique_lock<>可手动上锁,解锁更为灵活
std::mutex m1, m2;
std::unique_lock<std::mutex> ul1(m1, std::defer_lock); // std::defer_lock表示,不对mutex上锁
std::unique_lock<std::mutex> ul2(m2) // m2已自动上锁
ul1.lock(); // 手动上锁
保护数据的替代方案
保护共享数据的初始化过程
- 使用互斥量
std::mutex m;
std::shared_ptr<Widget> sp;
void Foo()
{
std::unique_lock<std::mutex> ul(m);
if(!sp)
{
sp.reset(new Widget);
}
ul.unlock();
sp->do_something();
}
std::once_flag和std::call_once
比用互斥量消耗的资源更少
std::shared_ptr<Widget> sp;
std::once_flag flag;
void Init()
{
sp.reset(new Widget);
}
void Foo
{
std::call_once(flag, Init);
sp->do_something();
}
// Init()只调用了一次
std::thread t1(Foo);
std::thread t2(Foo);
t1.join();
t2.join();
保护不常更新的数据结构
C++17提供std::shared_mutex和std::shared_timed_mutex,C++14只提供std::shared_timed_mutex,
而C++11并未提供。std::shared_timed_mutex更多操作方式,std::shared_mutex有更高的性能
std::shared_mutex sm;
void Foo()
{
// 其他线程加锁时,不会阻塞
std::shared_lock<std::shared_mutex> sl(sm);
...
}
void Foo2()
{
// 其他线程尝试加锁时,会阻塞
std::lock_guard<std::shared_mutex> lg(sm);
...
}
并行访问数据时,使用std::shared_lock<>上锁,所有线程都可对数据进行访问,而修改数据时,
使用std::lock_guard<>上锁,只有一个线程可以进行修改
限制:当有线程有共享锁(std::shared_lock<>上锁)时,独占锁(std::lock_guard<>)会阻塞,
而当有线程有独占锁时,其他独占和所有共享锁都会阻塞,直到独占锁解锁
嵌套锁
一个线程中std::mutex已经上锁后,再次上锁是错误的。而std::recursive_mutex,在同一线程可多次上锁
只不过,如果调用lock()三次,就需要unlock()三次,不过可以使用std::lock_guard<std::recursive_mutex>,或者
std::unique_lock<std::recursive_mutex>来管理
同步操作
条件变量
std::condition_variable或std::condition_variable_any
static std::condition_variable cond;
static bool flag = false;
static std::mutex m1;
void Prepare()
{
std::lock_guard<std::mutex> lg(m1);
flag = true;
cond.notify_one();
}
void Process()
{
std::unique_lock<std::mutex> ul(m1);
cond.wait(ul, [](){return flag;});
}
Process()中,如果cond.wait()的第二个参数为false,会解锁ul,并令线程阻塞,等待Process()中
的cond.notify_one()唤醒,唤醒后ul上锁,重新判断第二个参数的值,如果仍为false,就继续阻塞
template<typename Predicate>
void minimal_wait(std::unique_lock<std::mutex>& lk, Predicate pred)
{
while(!pred())
{
lk.unlock();
lk.lock();
}
}
future
std::future<>只移动,所有权在不同实例中互相传递
std::async
启动一个异步任务与std::tread相似,返回一个std::future<>对象。当使用get()或wait()函数时,会阻塞线程,直到future就绪即std::async
完成为止
int Foo();
std::future<int> result = std::async(Foo);
std::cout << result.get() << std::endl;
std::async的第一个参数有std::launch::deferred与std::launch::async
std::future<int> result1 = std::async(std::launch::deferred, Foo); // 在当前线程同步运行,直到get或wait时,才调用函数
std::future<int> result2 = std::async(std::launch::async, Foo); // 创建新线程异步运行,表示函数必须在独立线程上执行
std::future<int> result3 = std::async(std::launc::deferred | std::launch::async, Foo); // 由系统决定
result1.wait();
result3.wait();
std::async析构时,会阻塞线程,相当于同步执行
// 临时变量,用完后会析构,因此do_something会等到异步任务执行完才会执行
std::async([]{std::cout << "hello" << std::endl;});
do_something();
std::packaged_task<>
只是将可调用对象与future绑定,调用std::packaged_task对象会调用绑定的可调用对象
int Foo();
std::packaged_task<int()> task {Foo};
std::future<int> f = task.get_future();
task(); // 相当于执行Foo(),运行结束后f状态为就绪,即之后f.get()或f.wait()不会阻塞
std::cout << f.get() << std::endl;
可用于线程当中
int Foo();
std::packaged_task<int()> task {Foo};
std::future<int> f = task.get_future();
std::thread t(task);
...
f.wait(); // 阻塞线程,直到f就绪
...
t.join();
std::promise<>
可以将一个值传递给一个新线程
auto task = [](std::future<int> f) {
std::cout << f.get() << std::flush; // 阻塞,直到 p.set_value() 被调用
};
std::promise<int> p;
std::thread t{ task, p.get_future() };
std::this_thread::sleep_for(std::chrono::seconds(5));
p.set_value(5);
t.join();
std::shared_future<>
构造shared_future的方法
std::promise<int> p;
std::future f(p.get_future());
std::shared_future<int> sf(std::move(f));
std::promise<int> p;
std::shared_future<int> sf(p.get_future());
std::promise<int> p;
auto sf = p.get_future().share();
锁存器和栅栏
std::latch
- 计数器作为构造函数的唯一参数
std::latch la(3) count_down()与arrive_and_wait()令计数器减一,而后者会阻塞线程直到计数器为0wait()阻塞线程,直到计数器为0
std::barrier
- 计数器作为第一个参数,可调用对象(必须是noexcept)作为第二个参数(可选),在barrier就绪(计数器为0)时,
其中一个线程调用。同时,返回值指定下一次的计数
std::barrier b1(3); std::barrier b2(3, []() noexcept { std::cout << std::this_thread::get_id() << std::endl; return -1; // -1表示下一次计数不变 }); arrive_and_wait()令计数器减一,并且阻塞线程arrive()与wait(),b.arrive(b.wait())与b.arrive_and_wait()等价arrive_and_drop(),当前计数与下次barrier计数减一std::barrier可多次使用
内存模型和原子操作
atomic
atomic的操作都是原子的,有的是使用原子指令,有的使用互斥锁模拟原子操作,使用x.is_lock_free()
函数查询原子指令(is_lock_free()返回true)还是使用锁(is_lock_free()返回false)
同时C++17中,所有原子类型有一个static constexpr成员变量X::is_always_lock_free,值为true
表示无锁,false表示有锁
std::atomic_flag
唯一确保为无锁的类型
std::atomic_flag对象必须被ATOMIC_FLAG_INIT初始化。初始化标志位为清除状态即false
class spinlock_mutex
{
private:
std::atomic_flag flag;
public:
spinlock_mutex() : flag(ATOMIC_FLAG_INIT) {}
lock()
{
// test_and_set()设置标志位为true,并返回旧的标志位
// 第一次调用或着clear()后,才会返回false,从而调出循环
while(flag.test_and_set(std::memory_order_acquire));
}
unlock()
{
// 设置标志位为false
flag.clear(std::memory_order_release);
}
};
std::atomic<bool>
load(), store()与exchange()
atd::atomic<bool> b;
bool x = b.load(std::memory_order_acquire);
b.store(true);
// exchange()会返回旧值
x = b.exchange(true, std::memory_order_acq_rel);
compare_exchange_weak()和compare_exchange_strong()
CAS即Compare And Swap,
compare_exchange_weak()与compare_exchange_strong()是C++对CAS的实现
x.compare_exchange_strong(expected, desired),如果x的原始值(*this)与期望值(expected)相同,
则令x的值为desired,并返回ture,如果不同,则x的值不变,并将值赋给expected,返回false
返回值true或false表示x的值是否变化,与期望值相同则改变,不同则没变
bool expected = false;
extern std::atomic<bool> b;
if(b.compare_exchange_strong(expected, true))
{
...
}
对于compare_exchange_weak()来说,可能会出现"伪失败",即x.compare_exchange_weak(y, z),在
x与y相等时,仍然返回false,且将x的值赋给y。所以通常在使用compare_exchange_weak()时,都需要一个
循环
// x与expected相等时,如果伪失败,将x的值赋给expected后,再进行一次CAS
while(!x.compare_exchange_weak(expected, desired));
std::atomic<T*>
提供+=、-=、++、--操作,同时fetch_add()与fetch_sub()在加、减的基础上返回原来的值,称为
"交换-相加"
class Widget {};
Widget a[3];
std::atmoic<Widget*> p {a};
Widget* w1 = p.fetch_add(1); // p加1,而w1是p的原始值
std::atomic<>
原子操作的内存序
memory_order_relaxedmemory_order_consumememory_order_acquirememory_order_releasememory_order_acq_relmemory_order_seq_cst
除非指定一个选项,不然默认都是memory_order_seq_cst
6种选项代表三种内存模型:顺序一致性,获取-释放序(memory_order_consume, memory_order_acquire,
memory_order_release和memory_order_acq_rel)和自由序(memory_order_relaxed)
memory order针对的是共享变量,可以是atomic也可以是non-atomic的,但一定是共享的,通过 memory order约定CPU操作变量的顺序
顺序一致性
- 操作不重排,以源码的顺序执行
- 当前线程的操作顺序,对于其他线程可见
producer的线程中的代码顺序不会改变,即3先行于4,该顺序对consumer可见。因此在运行1 时,知道先运行3再运行4
std::atomic<bool> ready { false };
std::string work = " ";
void consumer()
{
while(!ready.load()); // 1
std::cout << work << std::endl; // 2
}
void producer()
{
work = "done"; // 3
ready.store(true); // 4
}
int main()
{
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
}
获取-释放序
在线程A上一个原子存储是释放操作,在线程B上对相同变量的原子加载时获得操作,且 线程B上的加载读取由线程A上的存储写入的值,则线程A上的存储Synchronizes-with(同步发生)线程B上的加载
- 不许acquire之后的操作重排到acquire之前,其他release同一原子变量的线程的所有 写入对当前线程可见
- 不许release之前的操作重排到release之后,当前线程的所有写入,可见于获得该同一 原子变量的其他线程
关于memory_order_consume,与memory_order_acquire一样,必须与memory_order_release一起使用,
然后就看不懂了,后续再补充
自由序
没有任何同步和重排限制
栅栏
对于lock()与unlock(),可以看作两个单方向的屏障,lock()只允许向下方移动,
unlock()只允许向上方移动

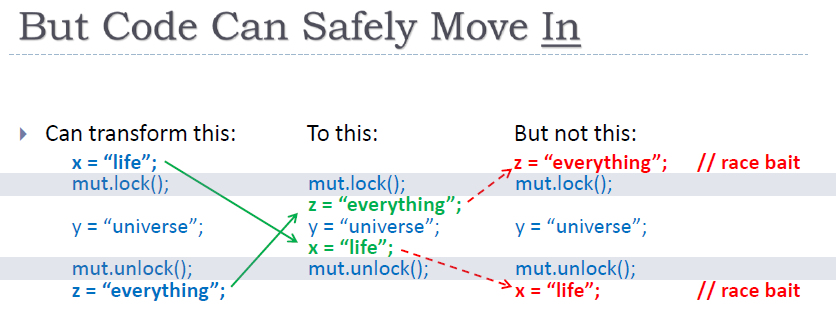
| full fence | acquire fence | release fence |
|---|---|---|
std::atomic_thread_fence() | std::atomic_thread_fence(std::memory_order_acquire) | std::atomic_thread_fence(std::memory_order_release) |
| 避免重排(Store-Load除外) | 避免栅栏前的读操作,被栅栏后的操作重排 | 避免栅栏前的写擦欧总,被栅栏前的操作重排 |
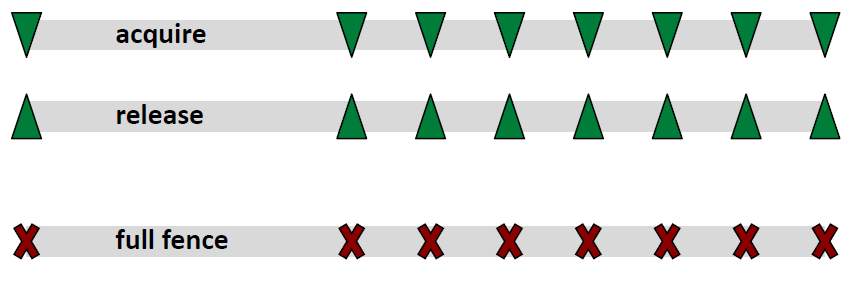
full fence

acquire fence

release fence

待续。。。有时间再看后面的