Effective Modern C++
CHAPTER 1 Deducing Types
条款1 理解模板类型推导
template<typename T>
// 此处ParamType泛指param的类型,可以是T,T&,const T&以及T&&
void f(ParamType param);
f(expr)
ParamType为指针或引用但不是通用引用
通用引用为T&&
- 如果expr为引用,则忽略引用部分
- 剩下的部分决定T,然后T与形参匹配得出ParamType
Template<typename T>
void f(T& param);
int x = 1;
const int cx = 1;
const int& rx = cx;
f(x); // T为int,param的类型为int&
f(cx); // T为const int,param类型为const int&
f(rx); // T为const int,param类型为const int&
ParamType是通用引用
- expr是左值,T和ParamType都是左值引用
- expr是右值,T为expr类型,ParamType为右值引用
ParamType既不是指针也不是引用
template<typename T>
void f(T param);
int x = 27;
const int cx = x;
const int& rx = cx;
// T和param都是int
f(x);
f(cx);
f(rx)
- 如果expr是引用,忽略引用部分
- 如果忽略引用后是const或volatile,它们也会被忽略
param只是expr的拷贝,expr不可修改,不代表param也一样函数实参传递给形参时,会忽略实参的顶层const
template<typename T> void f(T param); const char* const ptr = "Fun with pointers";
即T为const char*类型
数组实参
template<typename T>
void f(T param);
const char name[] = "Effective";
f(name);
此时,name会由数组退化成const char*指针即T为const char*类型。但同时也可用引用来表示数组
template<typename T>
void f(T& param);
f(name);
此时的T为数组引用类型,即const char(&)[10],同时我们可以在模板函数中推出数组大小
template<typename T, std::size_t N>
constexpr std::size_t arraySize(T (&)[N]) noexcept
{
return N;
}
函数实参
与数组一样,函数类型也会退化为函数指针
void someFunc(int, double);
template<typename T>
void f1(T param);
template<typename T>
void f2(T& param);
f1(someFunc); // ParamType为void(*)(int, double)
f2(someFunc); // ParamType为void(&)(int, double)
- 在模板类型推导时,引用会被忽略
- 对于通用引用的推导,左值实参会被特殊对待
- 对于传值类型的推导,实参的常量性和易变性会被忽略
- 在模板类型推导时,数组或函数会退化为指针,除非被用于初始化引用
条款2 理解auto类型推导 {#item2}
- auto类型拖到通常和模板类型推导相同,但auto类型推导假定花括号初始化代表
std::initializer_list而模板类型推导不这样做auto x = {1, 2, 3, 4}; // x的类型为std::initializer_list<int> template<typename T> void f(T param); f({1, 2, 3, 4}); // 不能推导出 template<typename T> void f(std::initializer_list<T> param); f({1, 2, 3, 4}); // 此时可推出 - 在C++14中允许出现在函数返回值或者lambda函数形参中,但它的工作机制是模板类型推导的方案
条款3 理解decltype
- decltype总是不加修改的产生变量或表达式的类型
- 对于T类型的左值表达式,decltype总是产出T的引用即T&
int a = 1; decltype(a); // int decltype((a)); // int& - C++14支持decltype(auto),就像auto一样,推导出类型,但它使用自己独特规则进行推导
单纯的auto与模板参数推导一样,会忽略引用
而在decltype(auto)中,auto说明类型会被推导,decltype说明会按decltype的规则推导
条款4 学会查看类型推导结果
CHAPTER 2 auto
条款5 优先考虑auto而非显示类型声明
条款6 auto推导若非己愿,使用显示类型初始化惯用法
- 不可见的代理类可能会使auto从表达式中推导出错误的类型
namespace std { template<class Allocator> class vector<bool, Allocator>{ public: class reference {...}; reference operator[](size_type n); } }
reference就是vector的代理类,当使用std::vector<bool> feature(const Widget&); auto highPriority = feature(w)[5];
此时期望的是highPriority为bool类型,但实际上auto推导的是std::vector<bool>::reference - 显式类型初始器惯用强制auto推导出想要的结果
auto highPriority = static_cast<bool>(feature(w)[5]);
CHAPTER 3 Moving to Modern C++
条款7 区别使用()和{}创建对象
- 括号初始化可防止变窄转换
括号初始化指的是大括号
- 在构造函数重载中,括号初始化会与
std::initializer_list参数匹配,即使其他构造函数时更好的选择class Widget { public: Widget(int i, double d); Widget(std::initializer_list<bool> il); }; Widget w{10, 5.0};
上述代码会匹配initializer_list参数的构造函数,而同时由于括号初始化禁止变窄转换,编译会失败 - 在模板类中选择使用小括号初始化或花括号初始化创建对象是一个挑战
std::vector<int> a(10, 20); // 10个20 std::vector<int> b{10, 20}; // 10和20
条款8 优先考虑nullptr而非0和NULL
条款9 优先考虑别名声明而非typedefs
- typedef不支持模板化,但是别名声明支持
- 别名模板避免了使用::type后缀,同时也就省去了typename的声明
template<typename T> struct MyAllocList { typedef std::list<T, MyAlloc<T>> type; }; MyAllocList<Widget>::type lw; // 在模板中还需要加上typename template<typename T> class Widget { typename MyAllocList<T>::type list; };
可直接使用usingtemplate<typename T> using MyAllocList = std::list<T, MyAlloc<T>>; MyAllocList<Widget> lw;
条款10 优先考虑限域枚举而非未限域枚举
条款11 优先考虑使用deleted函数而非使用未定义的私有声明
- 比起声明函数private但不定义,使用deleted函数更好
- 任何函数都能delete,包括非成员函数和模板示例
条例12 使用override声明重载函数
条款13 优先考虑const_iterator而非iterator
条款14 如果函数不抛出异常请使用noexcept
条款15 尽可能的使用constexpr
- constexpr对象是const,它的值在编译期可知。但不是所有const对象都是constexpr
int a; const int b = a; constexpr int c = b; // 错误,b的值编译期不可知 - 当传递编译期可知的值时,constexpr函数可以产出编译期可知的结果
constexpr函数的实参在编译期可知时,其结果将在编译期计算
constexpr函数被编译期不可知值调用时,他就像普通函数一样,在运行时计算
条款16 让const成员函数线程安全
条款17 理解特殊成员函数的生成
CHAPTER 4 Smart pointers
条款18 对于独占资源使用std::unique_ptr
- 默认情况,资源销毁通过delete,但支持自定义的删除函数。而有状态的删除器和函数指针会增加
std::unique_ptr的大小有状态是指有状态对象,就是有数据对象,可以保持数据,是非线程安全的
无状态就是一次操作,不能保存数据
可能是这样的 - 将
std::unique_ptr转化为std::shared_ptr是简单的
条款19 对于共享资源使用std::shared_ptr
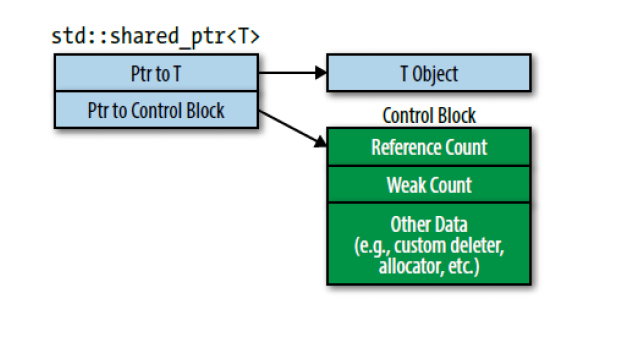
std::shared_ptr大小是原始指针的两倍,内部包含一个指向资源的原始指针,一个指向引用计数 的指针(指向控制块,控制块包含引用计数)- 引用计数必须动态分配
- 递增递减引用计数必须是原子性的
如果通过原始指针构造shared_ptr,需要直接传递new的结果
std::shared_ptr<Widget> sp(new Widget);
Widget* pw = new Widget;
// 会创建两个控制块,当spw1释放后,spw2会重复释放
std::shared_ptr<Widget> spw1(pw);
std::shared_ptr<Widget> spw2(pw);
当需要在类内部通过this构造shared_ptr时,需要使用share_from_this()
std::vector<std::shared_ptr<Widget>> widgets;
void Widget::process() {
// 会创建单独的控制块,造成重复释放
widgets.emplace_back(this);
}
class Widget: public std::enable_shared_from_this {
public:
void process();
};
void Widget::process() {
widgets.emplace_back(share_from_this());
}
条款20 当std::shared_ptr可能悬空时使用std::weak_ptr
条款21 优先考虑使用std::make_unique和std::make_shared而非new
std::make_shared是C++11标准,但std::make_unique在C++14,但可自己实现基础版本的std::make_unique
template<typename T, typename... Ts>
std::unique_ptr<T> make_unique(Ts&&... params)
{
return std::unique_ptr<T>(new T(std::forward<Ts>(params)...));
}
控制块还有第二个引用计数weak_count,只要std::weak_ptr引用一个控制块即weak_count大于零,
该控制块就必须存在。
使用make_shared创建对象时,对象销毁和释放内存之间会出现延迟
auto pBig = std::make_shared<BigType>();
... // 创建std::shared_ptr和std::weak_ptr指向对象
... // 当最后一个std::shared_ptr销毁,但std::weak_ptr还在
// 此时,先前分配给对象以及控制块的内存还未释放
... // 最后一个std::weak_ptr销毁
// 控制块和对象内存释放
直接使用new,一旦最后一个shared_ptr被销毁,对象的内存就会释放
auto pBig = std::shared_ptr<BigType>(new BigType);
... // 创建std::shared_ptr和std::weak_ptr指向对象
... // 当最后一个std::shared_ptr销毁,但std::weak_ptr还在
// 此时,对象销毁,分配给对象的内存释放
... // 最后一个std::weak_ptr销毁
// 控制块的内存释放
条款22 当使用Pimpl惯用法,请在实现文件中定义特殊成员函数
Pimpl是"指向实现的指针",通过将类的实现细节放在一个单独的实现类当中,类通过private指针类来访问实现类
// widget.h
#include <memory>
class Widget
{
public:
Widget();
~Widget();
Widget(const Widget&);
Widget& operator=(const Widget&);
Widget(Widget&&);
Widget& operator=(Widget&&);
private:
struct Impl;
std::unique_ptr<Impl> pImpl;
};
// widget.cpp
#include "widget.h"
struct Widget::Impl
{
int x, y;
};
Widget::Widget(): pImpl(std::make_unique<Impl>()) {}
Widget::~Widget() = default;
Widget::Widget(const Widget& rhs): pImpl(std::make_unique<Impl>(*rhs.pImpl)) {}
Widget& Widget::operator=(const Widget& rhs)
{
*pImpl = *rhs.pImpl;
return *this;
}
Widget(Widget&& rhs) = default;
Widget& operator=(Widget&& rhs) = default;
当一个Widget对象销毁时
- 会调用析构函数销毁pImpl
- pImpl调用默认删除器
- 默认删除器使用delete释放原始指针所指向的空间
在默认删除器中,delete之前会调用static_assert来确保原始指针指向的类型不是一个未完成类型,
因此应该在调用析构函数之前,让Impl为完整类型。即,将析构函数的定义写在Impl的定义下方
对于移动操作,需要销毁原来的对象,因此与析构相同
对于
std::shared_ptr来说,删除器的类型不是智能指针的一部分,在特殊函数(析构,移动)调用时, 不需要指向的对象是完成类型
CHAPTER 5 RValue References, Move Semantics and Perfect Forwarding
参数(parameter)永远是左值(LValue),即便它的类型是一个右值引用
条款23 理解std::move和std::forward
template<typename T>
typename remove_reference<T>::type&& move(T&& param)
{
return static_cast<remove_reference<T>::type&&>(param);
}
template<typename T>
void Foo(T&& param)
{
Test(std::forward<T>(param))
}
在对通用引用转发时,实参无论是左值还是右值,都会被T&&接受,但当接收右值时,param的类型为 右值引用,但此时param为一个左值,因此forward匹配的仍然是形参为左值引用的重载
template <typename T>
T&& forward(remove_reference<T>::type& param)
{
return static_cast<T&&>(param);
}
该重载只有在传入右值的时候才会匹配,并且返回右值
template <typename T>
T&& forward(remove_reference<T>::type&& param)
{
return static_cast<T&&>(param);
}
条款24 区分通用引用与右值引用
- 如果一个函数模板参数的类型为T&&,并且T需要被推导得知,或者如果一个对象被声明为auto&&,这个 参数或者对象就是一个通用引用
- 如果类型声明的形式不是标准的type&&,或者如果类型推导没有发生,那么type&&代表一个右值引用
模板里面的函数参数类型为T&&,并不一定会发生类型推导
template <typename T> class vector { public: void push_back(T&& param); }; std::vector<Widget> v;
实例化vector时就确定了push_back的声明
条款25 对右值引用使用std::move,对通用引用使用std::forward
按值返回的函数,并且返回值绑定到右值引用或通用引用上,需要对返回值的引用使用std::move或者 std::forward
lhs为左值,返回lhs会拷贝到返回值的内存空间,而如果lhs支持移动,使用std::move效率更高
Matrix operator+(Matrix&& lhs, const Matrix& rhs)
{
lhs += rhs;
// return lhs;
return std::move(lhs);
}
如果不带std::forward,frac类型为右值引用时,frac仍然为左值,return仍需要拷贝
template <typename T>
Fraction reduceAndCopy(T&& frac)
{
...
return std::forward<T>(frac);
}
C++标准存在返回值优化(RVO),即直接在返回值的内存中构造,来避免复制,也称为Copy elision
具名返回值优化NRVO,返回具名的局部变量
返回值优化的条件:1.局部变量与返回值类型相同;2.局部变量就是返回值
Widget makeWidget()
{
Widget w;
...
// 不满足要求2,std::move是对w的引用,而非局部变量,无法优化
// return std::move(w);
return w;
}
如果满足RVO的条件,但编译器选择不执行复制忽略,则必须将返回对象视为右值。标准要求RVO, 忽略复制或者将std::move隐式应用于返回的本地对象
因此上述代码中,return w;如果不执行复制忽略的优化,就会自动将std::move隐式执行
按值传递参数的情况于此类似,它们没有RVO的资格,但是如果作为返回值,编译器会将其视为右值
Widget makeWidget(Widget w)
{
return w;
// 实际上,编译器的代码为
// return std::move(w);
}
条款26 避免在通用引用上重载
class Person
{
public:
template<typename T>
Person(T&& n) : name(std::forward<T>(n)) {} // 通过名字构造
Person(int id); // 通过id构造
Person(const Person&);
Person(Person&&);
};
Person p1("Nancy");
Person p2(p1); // 调用的是通用引用的构造函数,而非拷贝构造
const Person p3("aaa");
Person p4(p3); // 正常匹配拷贝构造
class Person;
class SpecialPerson : public Person
{
public:
// 调用的都是Person的通用引用的构造函数
SpecialPerson(const SpecialPerson& rhs) : Person(rhs) {}
SpecialPerson(SpecialPerson&& rhs) : Person(std::move(rhs)) {}
};
完美转发构造函数是糟糕的实现,因为对于non-const左值不会调用构造函数而是完美转发构造, 而且会劫持派生类对于基类的拷贝和移动构造
条款27 熟悉通用引用重载的替代方法
Abandon overloading
重载虽然可以区分std::string与int,而采用不同的处理方式,但如果需要类型转换时,可能不能 起到期望的结果
template<typename T>
void LogAndAdd(T&& name)
{
names.emplace(std::forward<T>(name));
}
void LogAndAdd(int id)
{
names.emplace(GetNameById(id));
}
此时如果实参类型为short,模板函数的优先级大于形参为int的重载
因此可以不使用重载,分别改函数名为logAndAddName和logAndAddId,但是如果是构造函数的话, 就无法使用该方法
Pass by const T&
Pass by value
Use Tag dispatch
template<typename T>
void LogAndAdd(T&& name)
{
LogAndAddImpl(std::forward<T>(name), std::is_integral<std::remove_reference_t<T>>());
}
template<typename T>
void LogAndAddImpl(T&& name, std::false_type)
{
...
}
void LogAndAddImpl(int id, std::true_type)
{
...
}
Constraining templates that take universal references
class Person
{
public:
template<typename T, typename = std::enable_if_t<
!std::is_base_of_v<Person, std::decay_t<T>>
&&
!std::is_integral_v<std::remove_reference<T>>
>
>
Person(T&& n): name(std::forward<T>(n)) {...}
Person(int id): name(GetNameById(id)) {...}
};
Trade-offs
使用Person(u"hello"),其中实参为const char16_t,而不是char,此时调用的是通用引用的构造函数,
但其无法转换为std::string,因此需要提示错误信息
static_assert(std::is_constructible<std::string, T>::value, "message");
条款28 理解引用折叠
条款29 移动语义的缺点
条款30 熟悉完美转发的失败情况
template<typename... Ts>
void fwd(Ts&&... params)
{
f(std::forward<Ts>(params)...);
}
Braced initializers
void f(const std::vector<int>& v);
f({1, 2 , 3}); // 隐式转换为std::vector<int>
fwd({1, 2, 3}); // 无法编译
条款2中提到,在对fwd的调用中的{1, 2, 3}进行类型推导时,由于fwd的参数没有声明为std::initializer_list,
无法匹配。但auto却可以通过braced initializer推导出std::initializer_list
auto il = {1, 2, 3}; // il为std::initializer_list<int>类型
fwd(il);
0或者NULL作为空指针
仅声明的整数静态const数据成员
class Widget
{
public:
static const std::size_t Minvals = 28;
};
void f(std::size_t val);
fwd(Widget::Minvals); // 通过编译,但由于Minvals没有定义,无法链接
fwd的参数是通用引用,底层中,引用与指针是一样的,即通过引用传递Minvals实际上与使用指针转递
Minvals一样。但是static const在类中仅仅只是声明,而声明是不会分配内存的,即无法被指针指向。
从而,通过引用传递整型static const数据成员,必须定义它们
只是要求定义,并不是强制,因为有的编译器允许未定义的情况
重载的函数名称和模板名称
int Foo(int x);
int Foo(int x, int y);
f(int (*)(int));
fwd(Foo); // 无法判断选择哪个Foo
template<typename T>
T Foo(T param) {...}
fwd(Foo) // 无法判断那个Foo
位域
CHAPTER 6 Lambda表达式
条款31 避免使用默认捕获模式
闭包只会对lambda被创建时所在的作用域里的非静态局部变量生效,因此不能捕获成员变量
class Widget
{
private:
int m_value;
public:
void Test()
{
auto f = [=]() {return m_value;};
}
};
在成员函数类,相当于隐式捕获this,lambda中的m_value是this->m_value
void Widget::Test()
{
auto current_object_ptr = this;
auto f = [current_object_ptr](){return current_object_ptr->m_value;};
}
定义在全局空间或者指定命名空间的全局变量,或者是一个声明为static的类内或文件内的成员。 这些对象也能在lambda中使用,但它们不能被捕获
static int a = 1;
auto f = [=](){return a;};
++a;
虽然按值捕获,但并不能捕获a,在调用f()时,返回的是++a后的值,相当于是按引用捕获。 因此,在开始时就应该避免使用默认的按值捕获模式,以免误解
条款32 使用初始化捕获来移动对象到闭包中
C++ 14中可使用初始化捕获
class Widget;
autp pw = std::make_unique<Widget>();
auto func = [pw = std::move(pw)] {...};
C++ 11中可替代方法
- 闭包类
class Entity { public: explicit Entity(std::unique_ptr<Widget>&& ptr) : pw(std::move(ptr)) {} bool operator()() const { ... } private: std::unique_ptr pw; }; auto func = Entity(std::make_unique<Widget>()); - std::bind
using UniquePtr = std::unique_ptr<Widget>; UniquePtr pw = std::make_unique<Widget>(); auto func = std::bind([](const UniquePtr& ptr){...}, pw);
条款33 对于std::forward的auto&&形参使用decltype
auto f =
[](auto&&... params)
{
return func(normailized(std::forward<decltype(params)>(params)...));
}
条款34 考虑lambda表达式而非std::bind
- 与使用std::bind相比,Lambda更易读,更具有表达力并且可能更高效
- 只有在C++11中,std::bind可能对实现移动捕获或使用模板化函数调用运算符来绑定对象时会很有用
CHAPTER 7 并发API
条款35 优先基于任务编程而不是基于线程
std::thread不能直接访问异步执行的结果,如果执行函数有异常抛出,代码会终止执行- 基于线程的编程方式关于解决资源超限,负载均衡的方案移植性不佳
std::async会默认解决上面问题
条款36 确保在异步为必须时,才指定std::launch::async
使用wait_for() or wait_until()时考虑deferred状态
void Foo();
auto f = std::async(Foo);
// 当std::async使用std::launch::deferred时,会死循环
while(f.wait_for(1s) != std::future_status::ready) {
// ...
}
可以先判断一下是否为deferred
if(f.wait_for(0s) == std::future_status::deferred) {
// ...
} else {
while(f.wait_for(1s) != std::future_status::ready) {
// ...
}
}
条款37: 从各个方面使得std::threads unjoinable
class ThreadRAII {
public:
enum class DtorAction{ join, detch };
ThreadRAII(std::thread&& t, DtorAction a): action(a), t(std::move(t)) {}
~ThreadRAII() {
if(t.joinable()) {
if(action == DtorAction::join) {
t.join();
} else {
t.detach();
}
}
}
ThreadRAII(ThreadRAII&&) = default;
ThreadRAII& operator=(ThreadRAII&&) = default;
std::thread& get() { return t; }
private:
DtorAction action;
std::thread t;
};
析构时执行join()可能导致性能异常,执行detach()可能导致bug(详情见原书),
适当的解决方案是中断线程,详情见《C++ Concurrency in Action》9.2部分
条款38: 关注不同线程句柄析构行为
promise搭配future使用时,结果存储在共享状态*(shared state)中,而共享状态通常 是基于堆的对象
future的正常析构行为就是销毁future本身的成员数据- 最后一个引用
std::async创建共享状态的future析构函数会在任务结束前block
条款39: 对于一次性事件通讯考虑使用无返回 future
一个任务通知另一个异步任务执行的方法
- 条件变量
条件变量wait()语句存在虚假唤醒,即使条件变量没有被通知,也可能被唤醒, 可使用Lambda解决cv.wait(lk, []{return whether the event has occurred; }); - 共享的boolean标志
void Foo1() { std::atomic<bool> flag(false); // ... flag = true; } void Foo2() { // ... while(!false); // ... }
无锁以及没有虚假唤醒,但是Foo2()会一直占用CPU - promise与future
std::promise<void> p; void Foo1() { // ... p.set_value(); } void Foo2() { // ... p.get_future().wait(); // ... }
无锁,没有虚假唤醒,不会一直占用CPU,但std::promise与std::future间有共享 状态,并且共享状态是动态分配的,会有分配与释放的开销
同时,std::promise只能设置一次,即与std::future之间的通信是一次性的
条款40: 对于并发请使用std::atomic、volatile用于特殊内存区
std::atomic用在并发程序中volatile用于特殊内存的场景中,避免被编译器优化内存
CHAPTER 8 微调
条款41 如果参数可拷贝并且移动操作开销很低,总是考虑直接按值传递
std::vector<std::string> names;
// 1.重载 左值会由一次拷贝,右值由一次移动
void AddName(const std::string& newName)
{
names.push_back(newName);
}
void AddName(std::string&& newName)
{
names.push_back(std::move(newName));
}
// 2.通用模板 与重载开销相同
template<typename T>
void AddName(T&& newName)
{
names.push_back(std::forward<T>(newName));
}
// 3.按值传递 左值参数,一次拷贝一次移动,右值参数,两次拷贝
void AddName(std::string newName)
{
names.push_back(std::move(newName));
}
后面没看懂。。。
- 对于可复制,移动开销低,而且无条件复制的参数,按值传递效率基本与按引用传递效率一致,而且 易于实现,生成更少的目标代码
- 通过拷贝构造拷贝参数,可能比通过赋值拷贝开销大的多
- 按值转递会引起切片问题,所说不适合基类类型的参数
条款42 考虑使用emplacement代替insertion
也没怎么看懂
- 原则上,emplacement函数有时会比insertion函数高效,并且不会更差
- 实际上,当执行如下操作时,emplacement函数更快
- 值被构造到容器中,而不是直接赋值
- 传入的类型与容器类型不一致
- 容器不拒绝已经存在的重复值
- emplacement函数可能执行insertion函数拒绝的显示构造